Airbnb has disrupted the travel industry by providing a platform for people to list and book unique accommodations around the world. As the company continues to grow, effectively managing and analyzing the large amounts of data it generates is crucial. This article focuses on building an Extract, Load, and Transform (ELT) pipeline to process Airbnb data using the open-source workflow management tool Apache Airflow.
We’ll walk through setting up the required infrastructure on GCP and Snowflake, including creating a Cloud Composer environment and configuring connections. A multi-layer data warehouse architecture will be designed, and the ELT process will be automated using an Airflow DAG to refresh the tables. Business questions demonstrating analysis capabilities will also be covered.
Link to Github
- Datasets
- Infrastructure Setup
- Data Warehouse
- Automating ELT with Airflow
- Data Analysis
- Possible Improvements
Datasets
A 2022 version of AirBnB listings data for Sydney was used, which includes detailed information about the price, availability, location, property, host and review scores.
Census data was also used, from the 2021 G01 and G02 tables, available here. The G01 table from the Australian Census contains demographic information such as age and sex distribution for each Local Government Area (LGA), while the G02 table provides socioeconomic characteristics, including median age, income, mortgage repayments, and rent for each LGA.
Infrastructure Setup
To get started, a Google Cloud Platform (GCP) account and a Snowflake account are needed. Here’s a step-by-step guide to set up your environment:
Cloud Composer
-
Open Cloud Composer on the GCP account and enable the Cloud Composer API.
- Create a Cloud Composer environment (Composer 1) with the following parameters:
- Name: bde
- Location: australia-southeast1
- Machine type: n1-standard-2
- Disk Size (GB): 30
- Service Account: [default service account]
- Image Version: composer-1.19.12-airflow-2.3.3
The environment should take approximately 25 minutes to create.
-
Go to PYPI packages Install the required packages:
Name Version pandas snowflake-connector-python ==2.4.5 snowflake-sqlalchemy ==1.2.4 apache-airflow-providers-snowflake ==1.3.0 -
Next, add the following airflow configuration override:
Section 1 Key 1 Value 1 core enable_xcom_picking true
Connecting GCP to Snowflake
-
In the created Composer environment, upload the Census, LGA and at least one file (month) of AirBnB listing data in the Cloud Storage Bucket. Copy the file path to the data folder where the files were uploaded.
-
In a new Snowflake worksheet, create a database and a storage integration by specifying the file path above, as demonstrated in the query below.
CREATE STORAGE INTEGRATION GCP TYPE = EXTERNAL_STAGE STORAGE_PROVIDER = GCS ENABLED = TRUE STORAGE_ALLOWED_LOCATION = ('gcs://[FILEPATH TO DATA FOLDER]'); DESCRIBE INTEGRATION GCP;Retrieve the STORAGE_GCP_SERVICE_ACCOUNT from the output.
- On GCP, create a new ‘IAM and Admin’ role and add the following permissions:
- storage.buckets.get
- storage.objects.create
- storage.objects.delete
- storage.objects.get
- storage.objects.list
Assign this role to the Cloud Storage bucket by adding a principal for the STORAGE_GCP_SERVICE_ACCOUNT.
- On Snowflake, use the Admin menu to create a new (small) warehouse and then parse the URL to obtain the account and region. The URL can be in 2 possible formats:
- https://app.snowflake.com/[REGION]/[ACCOUNT]
- https://[ACCOUNT].[REGION].snowflakecomputing.com
- On GCP, open the Airflow UI in the Composer environment and create a new connection,by providing the Snowflake credentials below:
- Conn id: snowflake_conn_id
- Conn type: Snowflake
- Host: [ACCOUNT].[REGION].snowflakecomputing.com
- Database: [DATABASE_NAME]
- Account: [ACCOUNT]
- Region: [REGION]
- Warehouse: [WAREHOUSE_NAME]
- Password: [YOUR_SNOWFLAKE_PASSWORD]
A connection should now be established so Snowflake can access files stored in GCP.
Data Warehouse
A 4 layer data warehouse was designed for this data: Raw, Staging, Warehouse and Data Mart layers. Each layer is described below.
Raw Layer
The raw layer processes and stores data as it is read from the specified location.
- Create Stage: Set the storage integration to ‘GCP’ and the URL to the file path of the data folder.
- Create File Format: Define a file format that enables Snowflake to read CSV files.
- Create Raw Tables: Create separate raw tables for each dataset (Airbnb, Census G01, Census G02, LGA suburb, and LGA code data).
Note: Wildcards should be used when specifying the pattern (filenames), especially for files that will be updated and have their names in a similar format, so that Snowflake is able to capture all files that contain the same kind of data.
Staging Layer
Transforms raw data into structured data by specifying data types and column names.
- Airbnb Listings Data:
- Load text columns as varchar.
- Load ID and numeric fields as int.
- Load scraped_date as date.
- Load boolean columns as boolean.
- Load host_since and month_year as varchar (corrected later).
- LGA Suburb Data: Load both columns as varchar.
- LGA Code Data: Load lga_code as int and suburb_name as varchar.
- Census Tables: Load lga_code_2016 as int and other columns as decimal.
The host_since and month_year could not be loaded as date columns because the dates were not in a format that Snowflake recognized as a date. This was later corrected in the warehouse layer. Numeric columns were all loaded as decimal columns for convenience.
Warehouse Layer
Refines data in the staging tables into fact and dimension tables in a star schema. The ERD diagram shows the features and relationships between the tables.
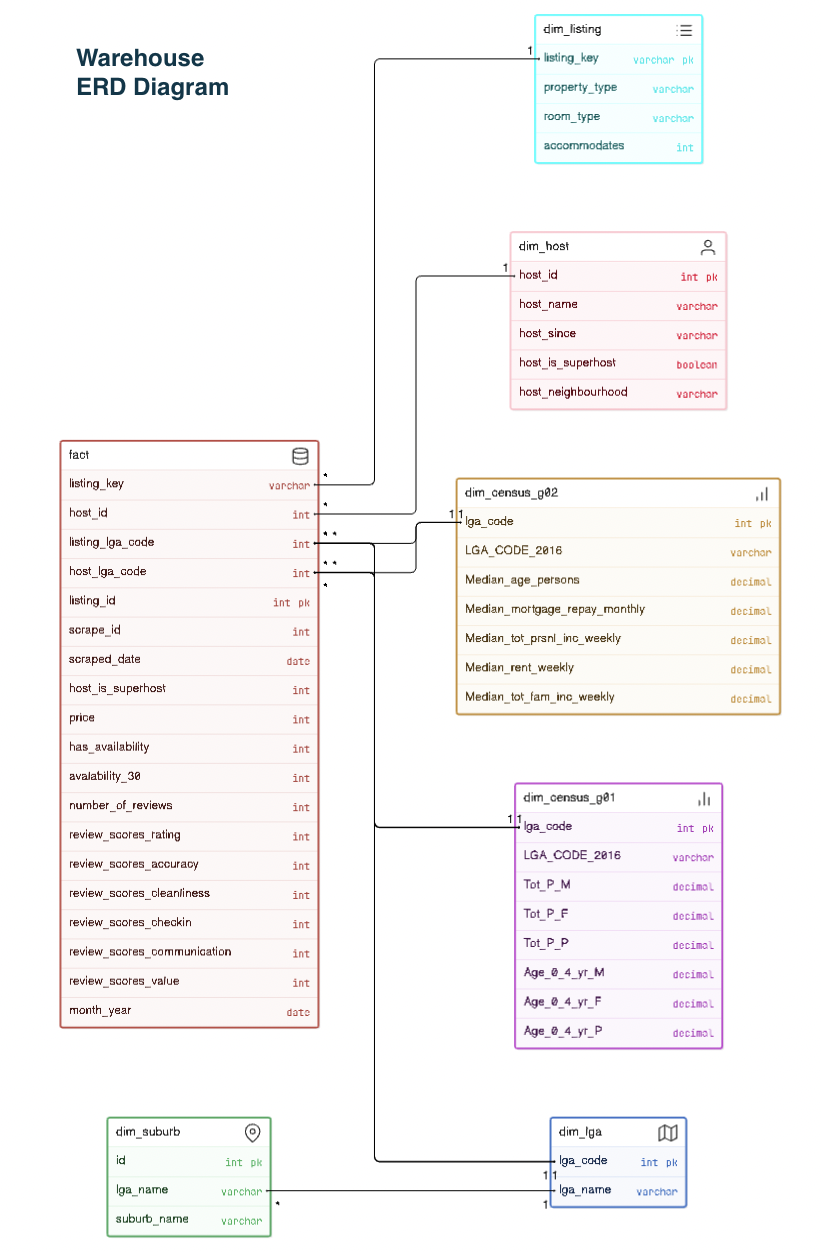
1. For the fact table, date columns were converted into dates and boolean columns included in binary format.
2. LGA codes were used to represent listing_neighbourhood and host_neighbourhood suburbs from the LGA tables, for storage efficiency.
3. A 'listing_key' was created, by taking the hash of the property features for mapping to the listing dimension table.
4. A Type 1 Slowly Changing Dimension (SCD) selected to update records for the host table by overwriting host data with the latest updates.
Data Mart Layer
Tables created to reflect aggregated properties of the Airbnb data.
- dm_listing_neighbourhood: For each listing_neighbourhood and month_year, the following properties were calculated:
- Active listings rate
- Minimum, maximum, median and average price for active listings
- Number of distinct hosts
- Superhost rate
- Average of review_scores_rating for active listings
- Percentage change for active listings
- Percentage change for inactive listings
- Total Number of stays
- Average Estimated revenue per active listings
-
dm_property_type: For each property type, room type, and accommodates, the above properties were calculated.
- dm_host_neighbourhood: For each host_neighbourhood_lga and month_year, the following properties were calculated:
- Number of distinct host
- Estimated Revenue
- Estimated Revenue per host (distinct)
Automating ELT with Airflow
Airflow enables the automation of populating and updating the data warehouse. To achieve this, a DAG file must be created to define the workflow’s structure and task execution flow. The steps to create the DAG file are as follows:
-
Define DAG File: Import relevant libraries, specify connection variables (e.g., snowflake_conn_id from Airflow connection interface), and define DAG settings (including start_date and schedule_interval).
-
Create SQL Query Strings: Define SQL queries to load data into the appropriate tables in the data warehouse. The queries are divided into three categories:
- Static Tables: Refresh the static tables (LGA and Census) by capturing new data in the raw table, and then recreate the corresponding staging and warehouse tables.
- Fact and Dimension Tables: Update the Airbnb data tables (fact, listing dimension, and host dimension) from the raw Airbnb data.
- Data Mart Tables: Refresh the data mart tables from the warehouse table.
-
Set Up DAG Operators: Create operators for each SQL query string, including task IDs, SQL queries, connection variables, and DAG settings.
-
Call DAG Operators: Execute the operators in the required order, ensuring all dependendencies, to refresh tables and update data:
refresh static tables -> refresh fact and dimension tables -> refresh datamart tables
Data Analysis
Several analysis were performed in line with the project requirements. The SQL queries used to gather the necessary information are provided below.
Population and Revenue in Listing Neighborhoods
The population of people under 30, in the best and worst performing listing neighborhoods, in terms of estimated revenue per active listing over the last 12 months, were compared.
| LISTING_NEIGHBOURHOOD | REVENUE_PER_LISTING | AGE_U35 | AGE_U25 |
|---|---|---|---|
| Fairfield | 15,647.860886 | 94,527 | 67,437 |
| Mosman | 111,966.95637 | 11,276 | 7,869 |
Given that the Census data did not contain an age range up to 30, we used the number of people under 25 (ages 20-24) and those above (ages 25-34). Fairfield, which has the lowest revenue per active listing, has a high population of people under 30. In contrast, Mosman, which has the highest estimated revenue per listing, has a significantly smaller population of people under 30. This suggests that Airbnb listings in neighbourhoods with a younger demographic tend to generate lower revenue.
Popular Listing Types in High-Revenue Neighborhoods
The type of listing (property type, room type, and accommodations) that has the highest number of stays in the top 5 neighborhoods, by estimated revenue per active listing, was determined.
| LISTING_NEIGHBOURHOOD | REVENUE_PER_ACTIVE_LISTING | PROPERTY_TYPE | ROOM_TYPE | ACCOMMODATES | TOTAL_STAYS |
|---|---|---|---|---|---|
| Mosman | 111,966.95637 | Entire apartment | Entire home/apt | 2 | 19,791 |
| Hunters Hill | 70,606.577592 | Entire apartment | Entire home/apt | 4 | 1,432 |
| Northern Beaches | 91,068.633817 | Entire apartment | Entire home/apt | 4 | 133,597 |
| Waverley | 67,780.659235 | Entire apartment | Entire home/apt | 2 | 214,352 |
| Woollahra | 82,771.916971 | Entire apartment | Entire home/apt | 2 | 58,328 |
Among these top-performing neighbourhoods, entire apartments are the most popular property type, having the highest number of stays. Specifically, smaller apartments that accommodate 2 or 4 people are the most preferred.
Host Listings by Neighborhood
The number of hosts with multiple listings in their own neighborhood was compared with the number of hosts with listings in different neighborhoods.
| ONLY_DIFFERENT_LGA | ONLY_SAME_LGA | TOTAL_SAME_GREATER_DIFFERENT | TOTAL_DIFFERENT_GREATER_SAME |
|---|---|---|---|
| 2,051 | 2,041 | 2,394 | 2,701 |
It was surprising to find that the number of hosts with listings only in their neighbourhood (2,041) was very close to those with listings only in different neighbourhoods (2,051). Overall, the number of hosts with multiple listings in different neighbourhoods slightly exceeds those with multiple listings in the same neighbourhood by less than 10%.
Revenue vs. Mortgage Repayment for Unique Listings
The number of hosts with a unique listing whose estimated revenue over the last 12 months covers the annualized median mortgage repayment of their listing’s neighborhood was calculated.
| CT_REVENUE_GREATER_MORTGAGE | CT_REVENUE_LESS_MORTGAGE | AVG_REV_GREATER_MORTGAGE | AVG_REV_LESS_MORTGAGE |
|---|---|---|---|
| 12,820 | 15,500 | 7,660.92 | -1,500.68 |
There were 12,820 hosts (45.3%) whose revenue exceeded the median mortgage repayment of their listing’s neighbourhood, with an average revenue of 7,660 more than the mortgage repayment. Conversely, 15,500 hosts (54.7%) had revenue less than the median mortgage repayment, with an average shortfall of 1,500 compared to their mortgage repayment.
Possible Improvements
-
SCD Design: While Type 1 SCDs were sufficient for the current business questions, retaining historical data with Type 2 SCDs could provide valuable insights for future analysis. However, this approach involves additional storage costs, which should be considered.
-
DAG File Optimization: The number of operations in the DAG files can be reduced to save costs. Once the initial data load is complete, it is unnecessary to update static tables like Census and LGA tables repeatedly. Removing these operations from the DAG will help reduce expenses.
-
Cost Tracking and Optimization: Monitoring the costs of running the Airflow environment is crucial, as it can become expensive. This can be done by navigating to ‘Billing’ on the GCP and reviewing the expenses. The ETL process should be optimized continually to minimize costs.